
영넌 개발로그
퍼셉트론의 개념 (단층 퍼셉트론 / 다층 퍼셉트론) 본문
퍼셉트론이란 ?
퍼셉트론은 다수의 신호를 입력으로 받아 하나의 신호를 출력한다. 쉽게 말하면 입출력을 갖춘 알고리즘이며 입력을 주면 정해진 규칙에 따른 값을 출력하는 것이다. 다시 말하면, 입력 값에 대해 출력 값이 어떻게 나올지 예측하는 기계이다. 입력->연산->출력 시스템이다.
이렇게 어떠한 것의 동작 원리를 정확히 파악할 수 없을 때 취할 수 있는 방식 중 하나는 우리가 조정할 수 있는 매개변수 값을 포함하는 모델을 만드는 것이다. 가중치와 편향을 매개변수로 설정한다. 매개변수를 포함하는 선형함수 모델을 만들어보자. 이후, 예측 값과 실제 값을 비교해 오차를 도출하고 이를 기준으로 조정한다.
퍼셉트론은 사람 뇌의 단일 뉴런이 작동하는 방법을 흉내내기 위해 환원 접근법 (reductionist approach)을 이용한다.초기 가중치를 임의의 값으로 정의하고 예측값의 활성 함수 리턴값과 실제 결과값의 활성 함수 리턴값이 동일하게 나올 때까지 가중치의 값을 계속 수정하는 방법이다.

기본적인 퍼셉트론의 경우, 초평면으로 n차원 공간을 두 개의 결정 영역으로 나뉜다. 초평면을 선형 분리 함수로 정의하며 식은 아래와 같다. 임계값 세타는 결정 경계를 옮기는 데 쓰인다.
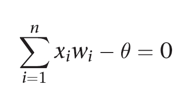
단층 퍼셉트론이란 ?
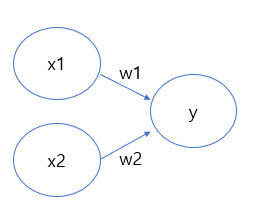
아래 그림에서 원을 뉴런 혹은 노드라고 부르며, 입력 신호가 뉴런에 보내질 때는 각각 고유한 가중치가 곱해진다. (w1,w2) 가중치는 각 신호가 결과에 주는 영향력을 조절하는 요소로 작용한다. 즉, 가중치가 클 수록 해당 신호가 그만큼 더 중요함을 뜻한다. 그 신호를 받은 다음 뉴런은 이전 뉴런에서 보내온 신호의 총합이 정해진 한계를 넘어설 때만 1을 출력한다. 그 한계를 보통 임계 값 (theta)이라 한다. 가중치를 갖는 층이 한 층이기 때문에 단층 퍼셉트론이라고 부른다. (문헌에 따라 층을 세는 기준은 다르다.)
이를 수식으로 나타내면 왼쪽과 같은 식이 된다. 오른쪽은 세타를 -b로 치환한 것이다. 여기에서 b를 편향(bias)이라 하며 w1과 w2는 그대로 가중치이다.

더 간결한 형태로 다시 작성해보자. 이를 위해서 조건 분기의 동작을 하나의 함수로 나타낸다. 이 함수를 h(x)라 하면 다음과 같이 표현할 수 있다. 이는 계단 함수(step function)의 형태를 띄고 있다.
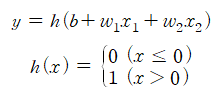
선형적 분류 (classifier) ?
선형함수(y=ax+c)는 말 그대로 입력 값을 받아 출력 값을 출력했을 때 그 형태가 직선으로 나오게 된다. 우리는 선형함수에서 매개변수 값인 a값과 c값을 조정함으로써 직선의 기울기와 위치를 변화 시킬 수 있다. 원래의 데이터를 통해 적절한 매개변수 값을 조정하여 직선의 기울기를 변화시키고, 이 직선(분류자)을 기준으로 미지의 데이터를 분류자를 기준으로 분류해낸다. 여기서 학습이 필요하다!
그렇다면 선형 분류자를 학습시켜서 잘 분류하게 하려면 어떻게 해야 할까? 임의의 선에서 시작해서 최적의 기울기를 찾는 과정이 학습이다. 우리는 실제 값을 가지는 예제 데이터에 기초해 분류자 함수의 기울기를 구하게 된다. 이 때 예제 데이터를 학습 데이터(training data)라고 부른다.
학습의 과정은 임의의 수로 시작하여 ‘오차’를 통해 기울기를 변화시킨다. 오차는 목표 값과 실제 출력 값 간의 차이이다. 그러나 직선이 오차만을 기준으로 업데이트한다면 최종적으로는 그저 마지막 학습 데이터에 맞춰진 업데이트 결과만을 얻게 된다. 이를 해결하기 위해 업데이트의 정도를 조금씩 조정할 수 있게 해주는 학습률(learning rate)에 대한 개념이 나오게 된다. 각각의 새로운 a로 바로 점프하는 것이 아니라 일부씩만 업데이트 하는 것이다. 즉 기존 여러 번의 학습에 기초해 업데이트된 값을 유지하면서, 학습 데이터가 제시하는 방향으로 조금씩만 움직이는 것이다. 이는 좋은 의미의 부작용도 수반한다. 실제 현업에서는 학습 데이터 자체에 문제가 있는 경우가 많고, 학습 데이터 자체가 오차 또는 잡음을 가지므로 완벽하게 정확하지도 않으며 심지어 신뢰할 수 없는 경우가 많이 있는데, 업데이트의 정도를 조정해가는 방법은 이러한 학습 데이터의 오차나 잡음의 영향을 약화시켜 준다.
이제 위에서 말로 설명한 것을 수식으로 봐보도록 하자.
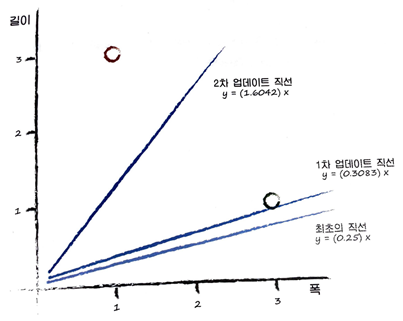
우선, y=Ax에 적정한 값을 넣고 시작하여 오차를 통해 매개변수 A를 조정한다.
이후 A를 정교화 하기 위해서는 여기서 오차 E와 기울기 A의 관계를 알아야한다. 아래의 수식을 살펴보자.
오차 E가 양수면 퍼셉트론의 출력을 증가하고, 음수면 퍼셉트론의 출력을 감소한다.
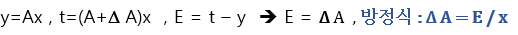
하지만 위와 같은 업데이트 방식은 마지막 학습 데이터에 맞춰진 결과만을 얻게 된다.
따라서 업데이트의 정도를 조금씩 조정하기 위해 학습률을 도입해보자. 그럼 아래와 같은 수식을 얻게 된다.
이때 학습률은 1보다 작은 양의 상수이다. 예를 들어 L=0.5이면, 조정이 없을 때에 비해 1/2만큼만 업데이트 하겠다는 의미이다.
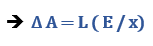
선형 분류자의 한계점
1. 직선형 영역만 표현할 수 있다. 데이터들의 차이가 확연히 두드러지지 않는다면 두 가지의 종류조차도 분류하지 못할 수도 있다는 말과 같다.
2. 단층 퍼셉트론에서 논리함수를 예로 들어보면, AND, NAND, OR 논리회로를 계산할 수 있지만 XOR(배타적 논리합)의 경우 단일 선형 프로세스로 데이터를 분류해낼 수 없다. 여러 개의 선형 분류자를 이용해서 데이터를 나누거나 한 선으로는 곡선으로 나눌 수 있기 때문에 비선형 분류이다.
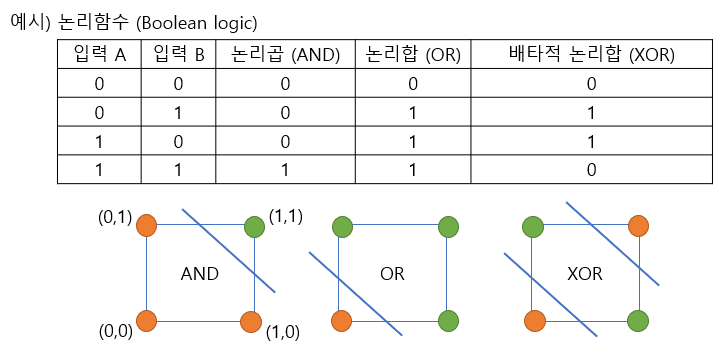

다층 퍼셉트론?
그래서 다층 퍼셉트론이 나왔다. (Multi-layer Perceptron, MLP)
단층 퍼셉트론은 입력층과 출력층만 존재하지만, 다층 퍼셉트론은 중간에 은닉층(hidden layer)이라 불리는 층을 더 추가하였다. XOR 게이트는 기존의 AND, NAND, OR 게이트를 조합하여 만들 수 있기 때문에 퍼셉트론에서 층을 계속 추가하면서 만들 수 있다. 이렇게 층을 여러겹으로 쌓아가면서 선형 분류만으로 풀기 못했던 문제를 비선형적으로 풀 수 있게 된다. 각 층에서 오차는 역전파 알고리즘을 통해 업데이트해나간다.
다층 퍼셉트론은 은닉층이 1개 이상인 퍼셉트론을 의미한다. 은닉층이 2개일 수도 있고 수십, 수백개일 수도 있다. 은닉층이 2개 이상인 신경망을 심층 신경망 (Deep Neural Network, DNN) 이라고 한다. 복잡한 문제를 해결하기 위해서는 신경망의 층수를 여러층 쌓은 모델을 이용해야 하는데, 깊은 층수를 쌓을 경우 역전파(Backpropagtion) 학습과정에서 데이터가 사라져 학습이 잘 되지 않는 현상인 Vanishing Gradient 문제가 있다. 또한, 학습한 내용은 잘 처리하나 새로운 사실을 추론하는 것, 새로운 데이터를 처리하는 것을 잘하지 못하는 한계도 있었다. 이러한 신경망을 '인공 신경망'이라고 부른다.
(학습과정과 현상에 대해서는 다음 포스팅에서 알아보도록 한다)
이러한 한계를 극복한 인공신경망을 딥러닝 (Deep Learning)이라고 한다. 캐나다 토론토 대학 제프리 힌튼(Geoffrey Hinton) 교수는 2006년에 깊은 층수의 신경망 학습시 사전 학습(Pretraining)을 통해서 학습함으로써 Vanishing Gradient 문제를 해결할 수 있음을 밝혔다. 또한 새로운 데이터를 잘 처리하지 못하는 문제는 학습 도중에 고의로 데이터를 누락시키는 방법(dropout)을 사용하여 해결할 수 있음을 2012년에 밝혔다.
'코딩 > ML , Deep' 카테고리의 다른 글
| 인공 신경망 수식 이해 (0) | 2021.01.18 |
|---|---|
| 다층 신경망 ( Artificial Neural Network, ANN) (0) | 2021.01.18 |
| 인공 신경망의 개념 / 활성화 함수 (0) | 2021.01.18 |
| 인공지능 / 머신러닝 / 딥러닝 개념 (0) | 2021.01.18 |



